


Blog:
Google Cloud Vision Evaluation - 2025 vs 2026
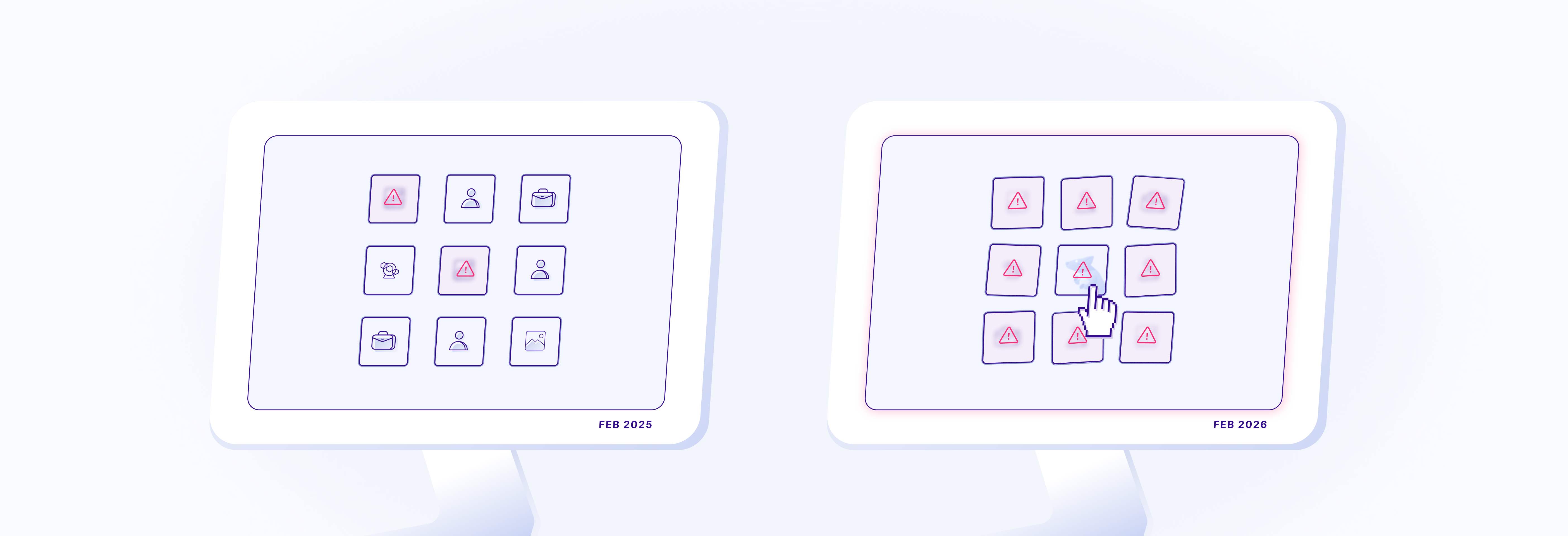

Automated image moderation systems are commonly used as a first-layer filter before human review. Services such as Google Cloud Vision (GCV) Safe Search aim to detect potentially sensitive content like adult imagery, violence, or suggestive material.
In February 2025, we evaluated Safe Search using a dataset of 552 images. One year later, we repeated the same experiment under identical conditions to compare the results and understand how moderation signals behave over time.
The flag rate increased from ~3% to ~79%, but the largest change between the two runs was not only the total number of false positives, but also their distribution by category.
In February 2025, false positives were limited and were mainly associated with violence:
In February 2026, the false positive profile changed completely:
This shows that the 2026 replication differed not only in volume, but also in how content was classified. It also behaved differently in terms of category assignment, with benign mouse images now being overwhelmingly classified as racy.
.png)
An example of a benign mouse image flagged as sensitive content.

Safe Search response:
{
"adult": "UNLIKELY",
"spoof": "VERY_UNLIKELY",
"medical": "UNLIKELY",
"violence": "POSSIBLE",
"racy": "UNLIKELY"
}
Despite containing no harmful content, the image triggered a moderation signal and required manual review.
This suggests Safe Search prioritizes explicit physical harm rather than weapon presence alone.
In 2025, Google Cloud Vision Safe Search appeared to be a reasonable first-layer moderation signal when used conservatively to trigger manual review.
However, the 2026 replication showed a very different behavior under the exact same conditions. The number of false positives increased from 15 to 435, with most of the new errors concentrated in the racy category.
Based on 2026 results, Safe Search is no longer operationally useful as a first filter for this dataset, since the volume of false positives generates too much unnecessary review workload. In practical terms, the system went from requiring manual review of approximately 3% of the dataset to nearly 80%, effectively removing the efficiency benefits of automated moderation.


